



The recently disclosed Meltdown and Spectre problems are not just significant security risks, Estimated Time Overhead Of System Calls On Linux also performance ones. The modifications used to mitigate Meltdown cause the most significant kernel performance regressions I’ve ever seen. Many thanks to the engineers who have worked tirelessly to create solutions for these processor problems.
In this post, I’ll look at the Estimated Time Overhead Of System Calls On Linux (KPTI) modifications that overcome Meltdown, as well as how to tweak them. A month ago, before we released in production, I did a lot of testing on Linux 4.14.11 and 4.14.12. Some earlier kernels include the KAISER fixes for Meltdown, and the performance overheads appear to be identical thus far. These findings are not final since further improvements, such as those for Spectre, are still being developed.
It should be noted that Meltdown/Spectre may have four levels of overhead, of which this is only one. They are as follows:
- KPTI patches from guests (this thread)
- Microcode updates from Intel
- Changes in cloud provider hypervisor (for cloud guests)
- Retpoline compiler modifications
Table of Contents
The KPTI Factors
There are at least five elements to consider while attempting to comprehend the KPTI overhead. To summarize:
Overheads are present in relation to the syscall rate, albeit large rates are required for this to be noticeable. The overhead may be 2% at 50k syscalls/sec per CPU and grows as the syscall rate increases. With a few exceptions (databases), high rates in the cloud are infrequent at my job (Estimated Time Overhead Of System Calls On Linux).
Context switches incur overheads comparable to syscalls, and I believe the context switch rate may be simply added to the syscall rate for the following estimates.
For high rates, the page fault rate adds a bit extra overhead.
More over 10 Mbytes of working set size (hot data) will incur extra overhead due to TLB flushing. This can increase a 1% overhead (only from syscall cycles) to a 7% overhead. This cost can be decreased by using A) pcid, which is fully functional in Linux 4.14, and B) Huge pages.
Cache access pattern: Certain access patterns that flip from caching well to caching a bit less well enhance the overheads. In the worst-case scenario, this can add an extra 10% cost, increasing (say) the 7% overhead to 17%.
To investigate this, I created a simple microbenchmark that allowed me to change the syscall rate and working set size (source). I then utilized various benchmarks to corroborate conclusions after analyzing performance during the benchmark (Estimated Time Overhead Of System Calls On Linux). More specifically:
1. Syscall frequency

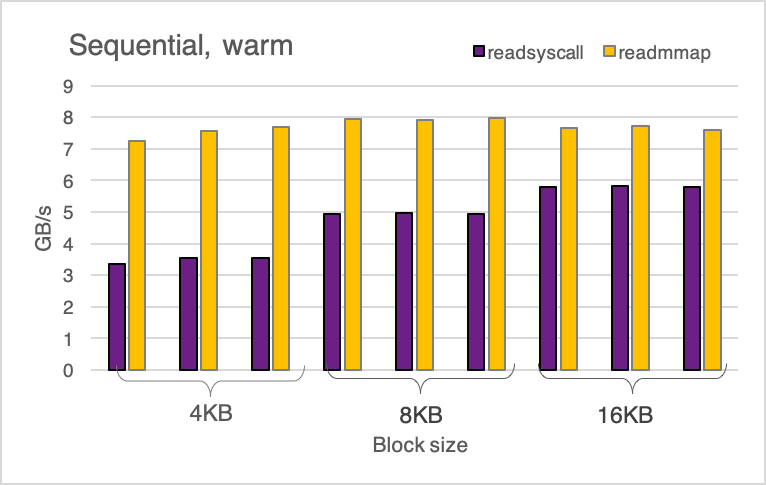
This is the price of additional CPU cycles in the syscall route. For my microbenchmark, I’m plotting the % performance loss versus syscall rate per CPU:
Proxy servers, databases, and other applications that perform a lot of little I/O are examples of applications with high syscall rates. Estimated Time Overhead Of System Calls On Linux, which often stress-test the system, will also incur the most losses. Many Netflix services are less than 10k syscalls/sec per Estimated Time Overhead Of System Calls On Linux, therefore this sort of cost is predicted to be insignificant (0.5%).
If you don’t know what your syscall rate is, you may measure it, for example, with perf:
perf stat -e raw_syscalls:sys_enter -a 1000
This displays the syscall rate for the entire system. Divide it by the number of CPUs (as provided by mpstat, etc.) to get the per-CPU rate. Then multiply by 1000 for the graph above. It should be noted that the perf stat command generates some overhead, which may be evident at high syscall rates (>100k/sec/CPU). If you like, you may use ftrace/mcount to measure it with less overhead. Using my perf-tools, for example:
The syscall column is then added up.
I could have taken one measurement and extrapolated the majority of the above graph using a model, but it’s always a good idea to double-check that there are no surprises. The graph is basically as predicted, with the exception of the lower right, which exhibits variation and missing data points: these missing data points are due to slightly negative values that the logarithmic scale omits. It’s tempting to dismiss this as a 0.2% error margin exacerbated by the logarithmic scale, but I believe much of it is due to the profile changing at this syscall rate (between 5k and 10k syscalls/sec/CPU). This will become clearer in the next parts, where I’ll go over everything in greater detail.
To imitate an application working set size, my microbenchmark calls a fast syscall in a loop, coupled with a user-level loop. The syscall rate falls as more cycles are utilized in a CPU-bound user-mode thread by progressively raising the time in the user-level loop from zero. This results in a spectrum that ranges from a high syscall rate of >1M/sec to a low syscall rate and largely user time (>99%). I then tested the syscall range with and without the KPTI patches (using nopti and running earlier and newer kernels to be sure).
I gathered CPU profiles as a CPU flame graph for both systems, but they were dull for a change: additional cycles were solely in the syscall code, as one would anticipate from reading the KPTI modifications. To have a better understanding of the overhead, I’ll need to employ instruction-level profiling, such as perf annotate, as well as PMC (Performance Monitoring Counter) analysis of the CPU cycles (Estimated Time Overhead Of System Calls On Linux).
2. Page Fault Rate & Context Switch Rate
The greater these rates, like with syscalls, the higher the overheads. For the estimation graphics on this page, I’d add the context switch rate (cswch/s) to the syscall rate (normalized per-CPU).
3. Working Set Dimensions (Estimated Time Overhead Of System Calls On Linux)
Now, my microbenchmark replicates a working set size (WSS) – a frequently used memory region – by looping through 100 Mbytes of data and striding by the cacheline size. Lower syscall rates significantly degrade performance:
Notice the “jump” in overhead between 10k and 5k syscalls/sec/CPU? The parameters of this leap depend on the instance type, processor, and workload, and can arise at different places with varying magnitudes: here is a c5.9xl with a 1.8% jump, however on a m4.2xl the jump is about 50k syscalls/sec/CPU and is significantly larger: 10% (seen here). This will be discussed more in the next section. We only want to look at the general trend here: much lower performance given a functional set.
Will your overhead look like this one, or the one before it, or worse? That depends on the size of your working set: this graph is for 100 Mbytes, while the previous was zero. See my earlier post on estimating working set size as well as the complete website. My assumption is that 100 Mbytes is a large-ish example of syscall-to-syscall memory required.
Linux 4.14 included complete pcid support, which helps speed if the CPU also has pcid (which appears to be frequent in EC2). Gil Tene explained why PCID is now a key performance/security feature on x86 in a blog post.

Update: As a commenter on this page noted out, earlier versions of Estimated Time Overhead Of System Calls On Linux, and/or I’ve heard manufacturers like Canonical have backported pcid fixes. I’ve subsequently tested the 4.4.115 kernel and validated its use of pcid. In detail, for a certain workload, booting with “nopcid” resulted in 8.4% DTLB and 4.4% ITLB miss walk handling, whereas booting with “pcid” resulted in 0.0% DTLB and 1.1% ITLB. So, yep, pcid works on 4.4 (at least on 4.4.115).
It is also possible to employ large pages to increase speed even more (either translucent gigantic pages, THP, which are simple to set up but have had compaction issues in previous versions; or explicit huge pages, which should work better). The possibilities are summarized in the graph below:
Despite KPTI, big pages enhanced performance so much for this microbenchmark that the performance loss was transformed into a performance gain. The negative points have been omitted from the logarithmic axis, but they are visible on the linear axis, zoomed in:Assume your server was doing 5k syscalls/sec/CPU and you assume you have a huge working set, as demonstrated by this 100 Mbyte test.
The performance cost on current LTS Estimated Time Overhead Of System Calls On Linux (4.4 or 4.9) with KPTI (or KAISER) modifications would be around 2.1%. Because Linux 4.14 includes pcid support, the overhead drops to around 0.5%. With large pages, the overhead becomes a 3.0% benefit.
A short glance at TLB PMCs explains most of this overhead: in this case, I’m using tlbstat, a simple utility I put together in my pmc-cloud-tools repository. The data that follow focus on a single point in the preceding graph (on a separate system with complete PMCs) where the worst case overhead from no KPTI to KPTI without pcid was 8.7%.
pti, pcid, and thp:
K_CYCLES K_INSTR IPC DTLB_WALKS ITLB_WALKS K_DTLBCYC K_ITLBCYC DTLB% ITLB% DTLB% ITLB%
- 2863464 2594463 0.91 2601 298946 57 6215 0.00 0.22
- 2845726 2568730 0.90 3330 295951 42 6156 0.00 0.22
- 2872419 2597000 0.90 2746 298328 64 6211 0.00 0.22
The final two columns show cycles in which at least one PMH (page miss handler) was active with a data TLB or instruction TLB walk. The first two results reveal TLB specifics for the 8.7% performance loss, with the additional TLB walk cycles accounting for 4.88% of all cycles. The remaining outputs demonstrate the inclusion of THP and the introduction of PCID. PCID minimizes both types of TLB walks, restoring data walks to pre-KPTI levels. Instructional walks remain high. The end result demonstrates the impact of big pages: data TLB walks are now nil. Instruction walks are still high, and I can see from /proc/PID/smaps that the instruction text isn’t utilizing enormous pages: I’ll try to remedy that with additional tweaking, which should increase speed even more.

Page walks consume half of the CPU cycles. I’ve never seen TLB pain this severe before. The IPC (instructions per cycle) alone indicates a problem: it has dropped from 0.86 to 0.10, which is related to the performance loss. As I stated in CPU Utilization is Wrong, I still propose incorporating IPC alongside (not instead of) any%CPU measurement so that you truly understand the cycles.
4. Pattern of Cache Access
At a specific syscall rate, an extra 1% to 10% overhead can arise depending on the memory access pattern and working set size. This was visible as the jump in the previous graph. One likely reason, based on PMC analysis and the description of the modifications, is increased page table memory consumption on the KPTI system, leading the workload to fall out of a CPU cache Estimated Time Overhead Of System Calls On Linux. The following are the key metrics:
This demonstrates that the performance loss leap corresponds to a comparable reduction in last-level cache (LLC) references (first two graphs): this is uninteresting because the lower reference rate is predicted from a reduced workload throughput. What’s remarkable is a sharp decline in LLC hit ratio, from about 55% to 50%, which does not occur without the KPTI patches (the final nopti graph, which shows a slight improvement in LLC hit ratio). The extra KPTI page table references appear to have pushed the working set out of a CPU cache, resulting in an abrupt loss in performance.
I don’t believe that a 55% to 50% decrease in LLC hit ratio can properly explain a 10% performance loss. Another issue is at work that would necessitate the use of additional PMCs to investigate; however, this target is a m4.16xl, and PMCs are limited to the architectural set. This is something I discussed in The PMCs of EC2: the architectural set is better than nothing, and we had nothing a year ago. Late last year, EC2 added two new alternatives for PMC analysis: the Nitro hypervisor, which offers all PMCs (or almost so), and the bare metal instance type (which is now in public preview). My previous TLB investigation was performed on a c5.9xl, a Nitro hypervisor system. Unfortunately, that system’s “jump” is just about 1%, making it difficult to detect outside of the typical variation.
In brief, there are certain extra memory overheads with KPTI that might cause workloads to exit CPU cache earlier.
Tests of Insanity
Putting these graphs to the test: a MySQL OLTP benchmark with 75k syscalls/sec/CPU (600k syscalls/sec across 8 CPUs) and a big working set (which more closely approaches this 100Mb working set test than the 0Mb one) was run. The graph estimates that KPTI’s performance loss (without big pages or pcid) is around 4%. The 5% performance decrease was measured. The measured performance loss on a 64-CPU system with the same workload and per-CPU syscall rate was 3%. Other testing, as well as the production roll out, were equally close.

An application with a stress test driving 210k syscalls/sec/CPU + 27k context-switches/sec/CPU and a tiny working set (25 Mbytes) resembled the previous graphs the least. The expected performance loss was less than 12%, but it was 25%. To ensure that there was no other source of overhead, I examined this and discovered that the 25% was due to TLB page walk cycles, which are the identical overheads researched previously. I believe the huge difference was caused by the fact that the application workload was more sensitive to TLB flushing than my basic microbenchmark.
Improving Performance
1. pcid and Estimated Time Overhead Of System Calls On Linux 4.14
This was noted before, and the difference was depicted in the graph. If you can run 4.14, it surely works with CPUs that enable pcid (see /proc/cpuinfo). It may work on some older kernels (such as 4.4.115).
2. Massive Pages
I also said that previously. I won’t go into detail on how to setup big pages with all of its drawbacks here because it’s a huge issue.
3. Reduced Syscalls
If you were on the more unpleasant end of the performance loss spectrum owing to a high syscall rate, the logical next step would be to investigate what those syscalls were and search for methods to minimize some of them. Many years ago, this was standard practice for system performance study, but more lately, the emphasis has shifted to user-mode victories.
Now that you know the most frequent syscalls, look for ways to reduce them. You can use other tools to inspect their arguments and stack traces (eg: using perf record, or kprobe in perf-tools, trace in bcc, etc), and look for optimization opportunities. This is performance engineering 101.
Conclusion and Further Reading
The KPTI patches to mitigate Meltdown can incur massive overhead, anything from 1% to over 800%. Where you are on that spectrum depends on your syscall and page fault rates, due to the extra CPU cycle overheads, and your memory working set size, due to TLB flushing on syscalls and context switches. I described these in this post, and analyzed them for a microbenchmark. Of course, nothing beats testing with real workloads, and the analysis I’ve included here may be more useful in explaining why performance regressed and showing opportunities to tune it, than for the estimated regressions.
In practice, I expect the cloud systems at my employer (Netflix) to experience 0.1% to 6% overhead with KPTI due to our syscall rates, and I expect that to be reduced to less than 2% with tuning: using 4.14 with pcid support, huge pages (which can also provide some gains), syscall reductions, and whatever else we find.
This is only one out of four potential sources of overhead from Meltdown/Spectre: there’s also cloud hypervisor changes, Intel microcode, and compilation changes. These KPTI numbers are also not final, as Estimated Time Overhead Of System Calls On Linux is still being developed and improved.